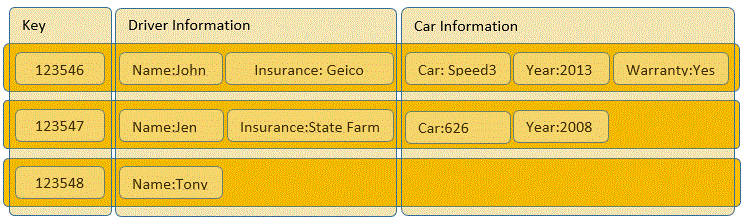
Well Rick Krueger( blog | @DataOgre ) and I are back at it again. We have decided to pair up and do a talk about a rather controversial topic in the SQL Server community, NoSQL. Now we are not jumping ship and saying that NoSQL is the way of the future, because that is simply not true. Relational databases have been around since the 70′s and still outperform NoSQL Solutions at most tasks. The idea that we are going to seed is that these NoSQL solutions may have a place in enterprise applications. We are not going to say you should use SQL Server or a NoSQL Solution exclusively, rather we are going to claim Polyglot Persistence. Polyglot Persistence is the idea of using multiple data stores to solve multiple problems, hence Rules of Engagement: NoSQL is SQL Server’s Ally. In a previous blog post I discussed Key Value Stores and Column Stores, in this blog post I will be discussing another version of the NoSQL solutions, Graph Databases.
Graph Databases
Graph Databases are data structures that consist of nodes, properties, and edges. In RDBMS terms a node would be a record in a table, a property would be the data within the record, and an edge would be similar to the relationship between tables. However the edges can store properties too, these properties describe the relationship between the nodes.
In the RDBMS land, writing queries to join many large tables, especially self referencing tables, can degrade performance of a query and can be rather costly, even with proper index usage. This is where Graph databases really shine, the graph databases has the ability traverse nodes using the edges and the properties within the edges. Using Graph Database to find relationships between highly interconnected data is very fast. Finding data that would take multiple joins or a recursive query in a RDBMS is a simple task with Graph Databases.
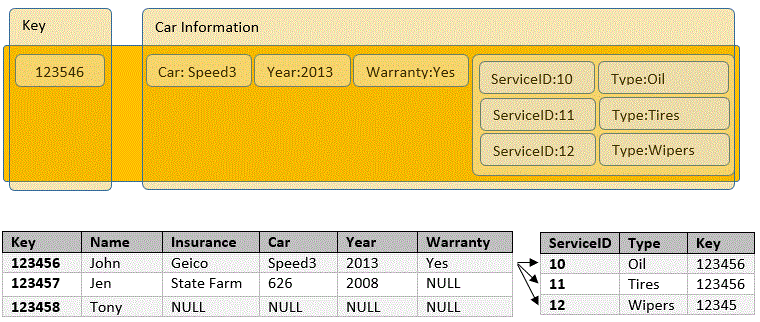
You can visualize a graph database as a flattened RDBMS table structure with named connections. Looking at the the relational tables below we see simple car buying and selling database. This database has a list of cars that people currently own and the types of cars they are looking for.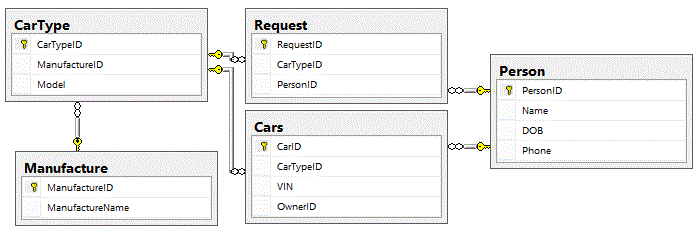 If we were to flatten and denormalize the structure we would get something that looks like this.
If we were to flatten and denormalize the structure we would get something that looks like this.
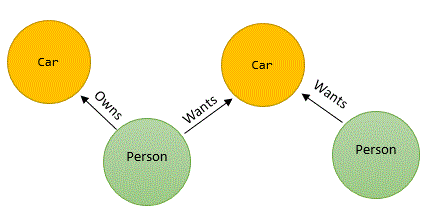
Here the Car node is the CarType and Manufacture tables denormalized, the Person node is the Person table, and the edges that connect these two nodes would be the Request and Cars tables. Depending on the data you are looking for, both of these structures have their merits. Lets say you need to write a query that will return a list cars for a given owner that is willing to trade with another owner. This is a simple query for both, however what if there is not a match, but there is a match using a 3rd party for a trade. Or maybe there needs to be a 4th or 5th party for a four or five way trade. This query is starting to get very complicated in a RDBMS, and the performance at each level is progressively degrading. This is where a Graph Database is really going to stand out! Being that the emphasis is on the edges between the nodes, the query is simple and will give you performance your application will desire.
Graph Database Implementations
One of the most recognized Graph Databases implementations is Neo4j and is currently made available by Neo Technologies.
“Neo4j is a robust (fully ACID) transactional property graph database. Due to its graph data model, Neo4j is highly agile and blazing fast. For connected data operations, Neo4j runs a thousand times faster than relational databases.” – http://www.neo4j.org/
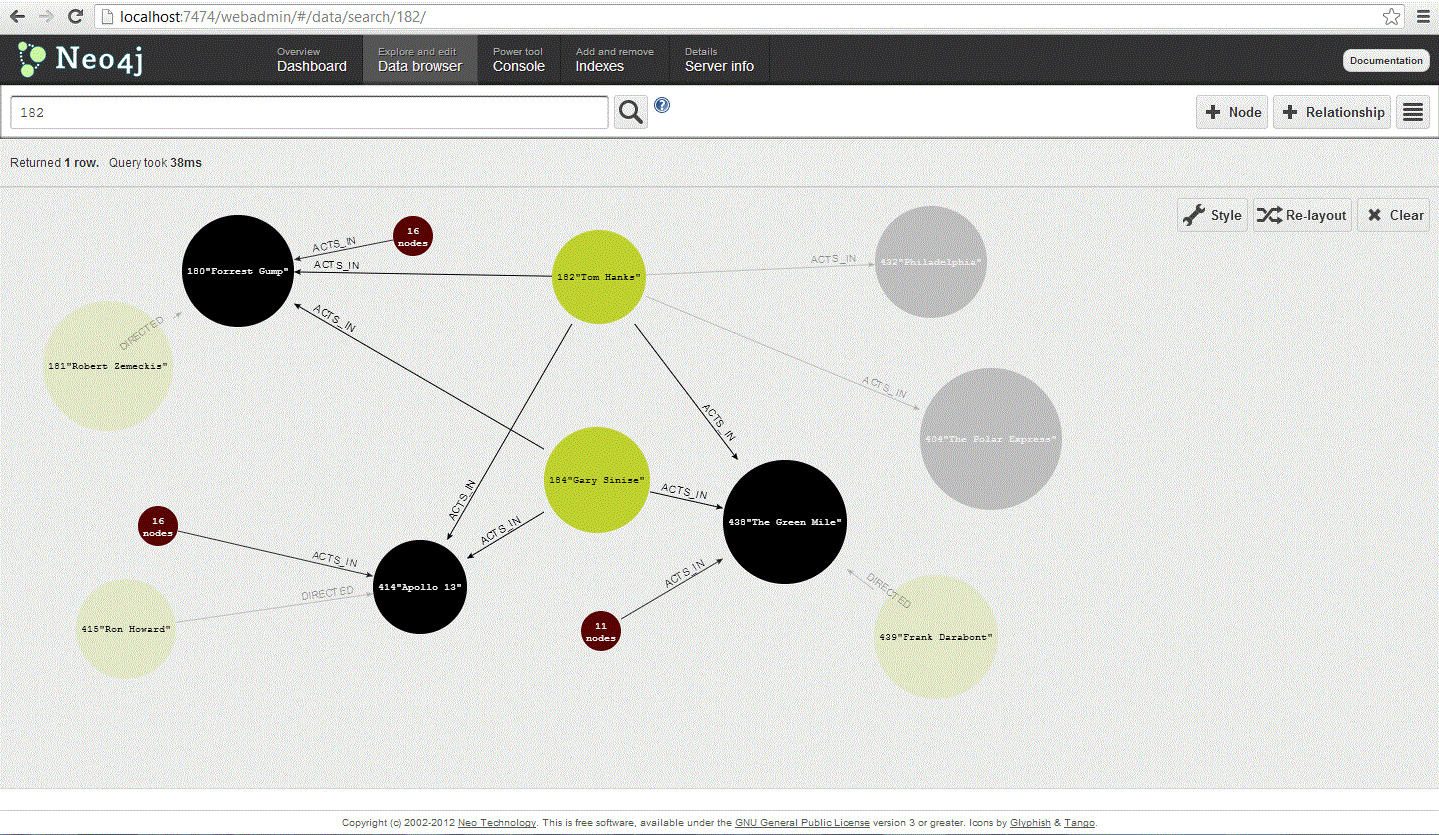
Neo4j is available for most platforms and comes with a WebAdmin management console for viewing the graph database. Below are some screen captures of the Web Admin utility showing a Dashboard for over all database health, and some ways to view the data inside the database.
Polyglot Persistence, SQL Server and Graph Databases
Recently Facebook announced a graph search feature in their application.
“With graph search you can look up anything shared with you on Facebook, and others can find stuff you’ve shared with them.” – https://www.facebook.com/about/graphsearch
This is idea of using a graph database within their application is the idea behind polyglot persistence. Their primary data could be stored in any data structure such as a RDBMS, but their graph search feature would be stored in a Graph Database.
Conclusion
I am not recommending that you re-write your applications to make room for a NoSQL solution, I am simply suggesting that you as the DBA (keeper of data), should keep an open mind to other possibilities. If there is another solution out there that could assist SQL Server, or is maybe a better fit, exploring the avenue might result in a better data solution. As always, a round peg will fit into a square hole if you have a big enough hammer.